


2025年9月29日、中国AI技術企業のディープシーク(DeepSeek)は、DeepSeek-V3.2-Expモデルを正式リリースした。このモデルは、その名称が示す通り、V3.2を基にした実験的(Experimental)なバージョンだ。
次世代アーキテクチャーへ向けた中間ステップとして、DeepSeek-V3.2-ExpはV3.1-Terminusを基盤に、DeepSeek Sparse Attention(スパースアテンション機構) を新たに導入した。これにより、長文テキストの訓練と推論の効率性を探求的に最適化し検証している。
このDeepSeek Sparse Attention(DSA)は、細粒度のスパースアテンション機構を初めて実現したものとされ、モデルの出力効果にほとんど影響を与えることなく、長文テキストの訓練と推論効率の大幅な向上を実現した。
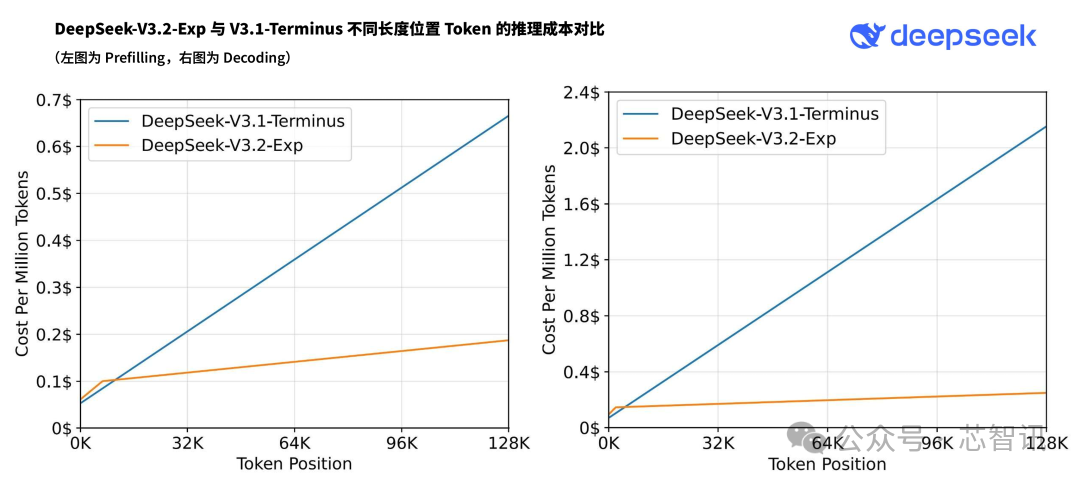
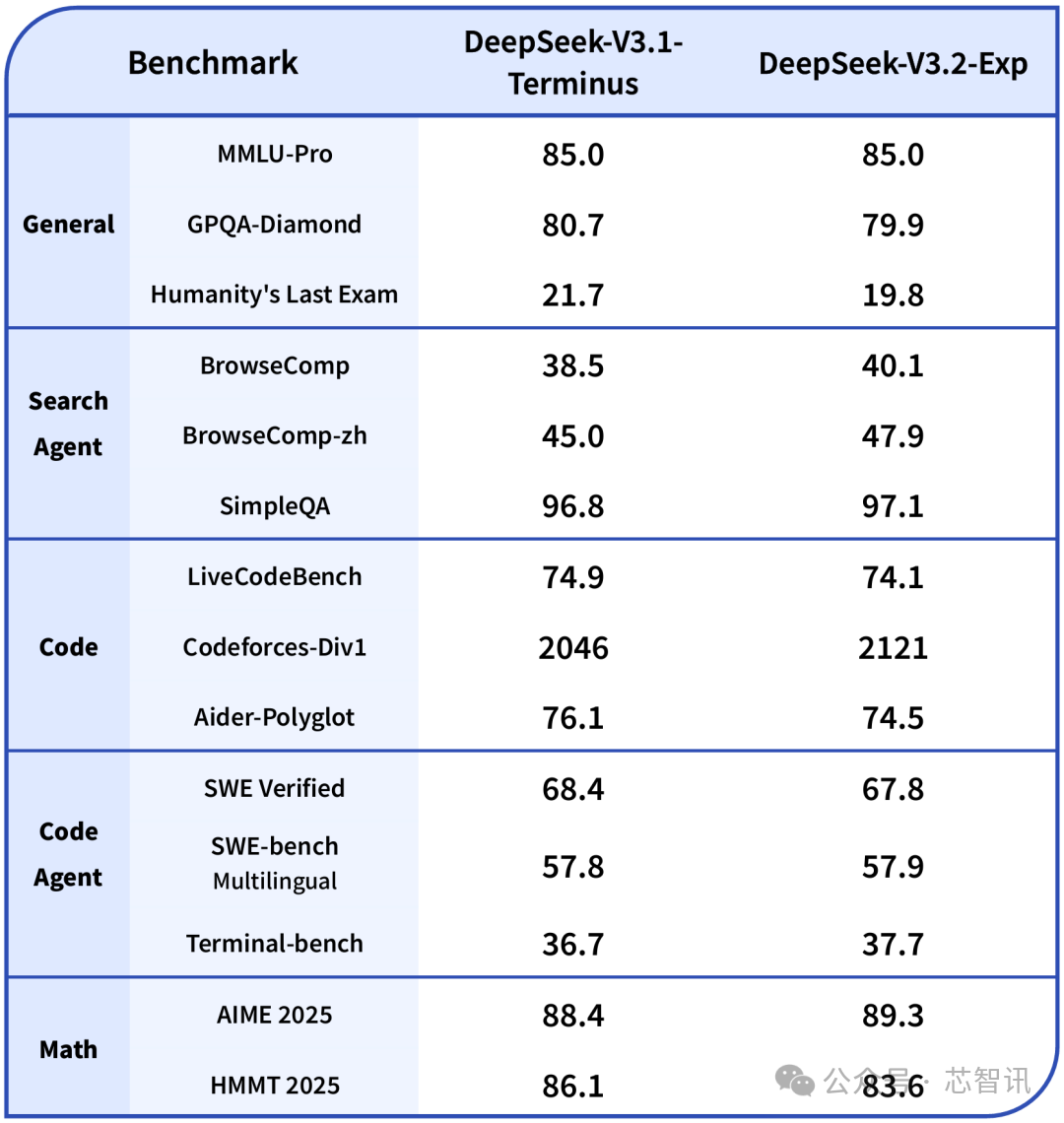
スパースアテンション導入の影響を厳密に評価するため、DeepSeek-V3.2-Expの訓練設定はV3.1-Terminusと厳密に揃えられた。各分野の公開ベンチマークテストにおいて、DeepSeek-V3.2-ExpのパフォーマンスはV3.1-Terminusとほぼ同等を維持している。
現在、DeepSeek公式App、ウェブ端末、ミニアプリは全てDeepSeek-V3.2-Expに同時更新され、さらにAPI価格が大幅値下げされた。
特筆すべきは、DeepSeek-V3.2-Expモデルがリリースされた同日に、中国AIチップ大手「寒武紀(Cambricon)」が、DeepSeek-V3.2-Expへの適応を完了し、大規模モデル推論エンジンvLLM-MLUのソースコードをオープンソース化したと発表したことだ。
これにより、開発者は寒武紀(Cambricon)のソフトウェア・ハードウェアプラットフォームで、DeepSeek-V3.2-Expの特長をいち早く体験できるようになった。
寒武紀(Cambricon)は、チップとアルゴリズムの連合革新を重視し、ソフトウェア・ハードウェア協調の方法で大規模モデルの展開性能を最適化し、展開コストを削減することに尽力していると表明している。
これまでカンブリア紀はDeepSeekシリーズモデルに対し、深いソフトウェア・ハードウェア協調性能最適化を実施し、業界をリードする演算能力利用率レベルを達成してきた。
今回のDeepSeek-V3.2-Expという新モデルアーキテクチャに対し、寒武紀(Cambricon)はTritonオペレーター開発による迅速な適応を実現し、BangC融合オペレーター開発を用いて性能最適化を図り、計算と通信に基づいて、業界をリードする計算効率水準を再び達成した。
寒武紀(Cambricon)は、DeepSeek-V3.2-Expがもたらす全新しいDeepSeek Sparse Attentionメカニズムと、自社の計算効率とが相まって、長シーケンスシナリオにおける訓練と推論のコストを大幅に削減し、顧客に競争力のあるソフトウェア・ハードウェア・ソリューションを提供できると示している。
(原文:https://www.icsmart.cn/96934/)