

2025年12月20日、北京–摩爾線程(Moore Threads)初のMUSA Developer Conference(MDC 2025)が北京・中関村国際イノベーションセンターにて正式に開幕した。中国国内初のフル機能GPUに焦点を当てた開発者向け技術イベントとして、同カンファレンスでは、独自開発のMUSA統一アーキテクチャを中核とする同社のフルスタック技術成果が体系的に展示され、ハイエンドフル機能GPU分野における同社の重要なブレークスルーと先見的な戦略的展開を全面的に披露した。

Moore Threads創業者、会長兼CEOの張建中(チョウ・ケンチュウ)氏は基調講演において、フル機能GPUの基盤としてのMUSAアーキテクチャの先進性と技術的リーダーシップを強調し、次のように述べた。「エコシステムはGPU業界における核心的な競争優位性と価値の源泉です。MUSAアーキテクチャの優位性を活かし、我々はハードウェアからソフトウェアに至る中核技術課題の克服に向け研究開発投資を継続的に拡大するとともに、オープンイノベーションを通じてエコシステムパートナーとの連携を深化させ、国内コンピューティング産業エコシステムの共創に取り組んでいます。今回のカンファレンスは業界初のフル機能GPUに特化した開発者向け大規模イベントであり、皆様の熱意に大いに励まされています。より多くの開発者と力を合わせ、MUSAエコシステムの繁栄と発展を推進することを期待しています」という。
今回の発表における核心的成果は以下の通り:
1.フル機能GPUアーキテクチャ「花港(Flower Harbor)」:FP4からFP64までの全精度計算をサポートし、演算密度は50%向上し、エネルギー効率は10倍向上する。将来的に、このアーキテクチャに基づき、高性能AI学習・推論統合チップ「華山」および高性能グラフィックスレンダリング専用チップ「廬山」を投入予定。
2. 「誇娥(KUAE)万卡」高効率トレーニング:「誇娥万卡」インテリジェントコンピューティングクラスターを発表し、兆規模パラメーターモデルの学習を支えるエンジニアリング能力と信頼性を実証。複数のキー精度指標において国際的主流レベルを達成。
3. 推論性能の飛躍的向上:Moore Threadsはシリコンベースのフロー(SiliconFlow)と連携し、DeepSeek R1 671Bフルモデルにおいて性能ブレークスルーを達成。MTT S5000シングルカードで、Prefillスループットが4000 tokens/s、Decodeスループットが1000 トークン/秒を突破し、国内推論性能の新たなベンチマークを確立。
4.超ノードアーキテクチャの展望:次世代超大規模インテリジェントコンピューティングセンター向けのMTT C256超ノードアーキテクチャを共有。高密度ハードウェアアーキテクチャに焦点を当て、知能計算性能を実現。
5.次世代パーソナルAIコンピューティングプラットフォーム:自社開発の第一世代インテリジェントSoCチップ「長江」を搭載したAI演算ノートPC「MTT AIBOOK」を正式発表。「Moore Threads Academy(摩尔学院)」の20万人の開発者・学習者に力を付与。
6.グラフィックスの進化と最先端探求:ハードウェアレベルでのレイトレーシング高速化技術および自社開発のAI生成型レンダリング技術を披露。エンボディドAI、AI for Science(AI4S)、AI for 6Gなどの最先端分野への深い布陣を明らかにし、フル機能GPU技術ロードマップの幅広さと将来に向けた拡張性をさらに裏付け。
これら一連の成果の発表は、Moore Threadsが独自の統一アーキテクチャを基盤とし、「チップ・エッジ・エンドポイント・クラウド」を貫通する完全な技術スタックの構築に成功し、低層ハードウェアから上層アプリケーションに至るシステマティックな閉ループを実現したことを示している。この体系は、中国国産インテリジェントコンピューティングエコシステムの持続的進化と産業融合に対し、オープンで持続可能なプラットフォームレベルのサポートを提供する。
戦略的基盤:MUSA統一アーキテクチャの進化と開放
MUSA(Meta-computing Unified System Architecture)は、Moore Threadsが独自開発したメタコンピューティング統一計算アーキテクチャで、チップアーキテクチャ、命令セット、プログラミングモデルからソフトウェアランタイムライブラリ及びドライバーフレームワークに至るまでのフルスタック技術体系をカバーしている。

MUSAはチップ設計からソフトウェアエコシステムまでの統一技術標準を完全に定義するだけでなく、同社が基盤技術革新を堅持し長期主義を実践する戦略的核を体現し、フル機能GPUの強固な技術基盤を築いている。これによりAI計算、グラフィックスレンダリング、物理シミュレーション、科学計算、超高解像度動画コーデックなど全シナリオにおける高性能計算を効率的にサポートする。
ハードウェアコア:新アーキテクチャ「花港(Flower Harbor)」と技術ロードマップ
MUSA統一システムに基づき、Moore Threadsは次世代フル機能GPUアーキテクチャ「花港」を披露した。新世代命令セットを採用し、FP4からFP64までの全精度計算をサポートし、演算密度は50%向上し、エネルギー効率は10倍向上した。同時に、本アーキテクチャは全精度エンドツーエンド高速化技術、次世代非同期プログラミングモデル(APM)、10万カード規模を超えるインテリジェントコンピューティングクラスターをサポートする。グラフィックス能力においては、「花港(Flower Harbor)」は第一世代AI生成型レンダリングアーキテクチャ(AGR)、第二世代ハードウェアレイトレーシング高速化エンジンを採用し、DirectX 12 Ultimateを完璧にサポートする。さらに、「花港(Flower Harbor)」は自律制御とセキュリティ性においても一段と向上している。

⦁ 計算性能の大幅向上:次世代命令セットに基づき、演算密度は50%向上、エネルギー効率が大幅に最適化。FP4からFP64までの全精度エンドツーエンド計算をサポートし、新たにMTFP6/MTFP4及び混合低精度サポートを追加する。
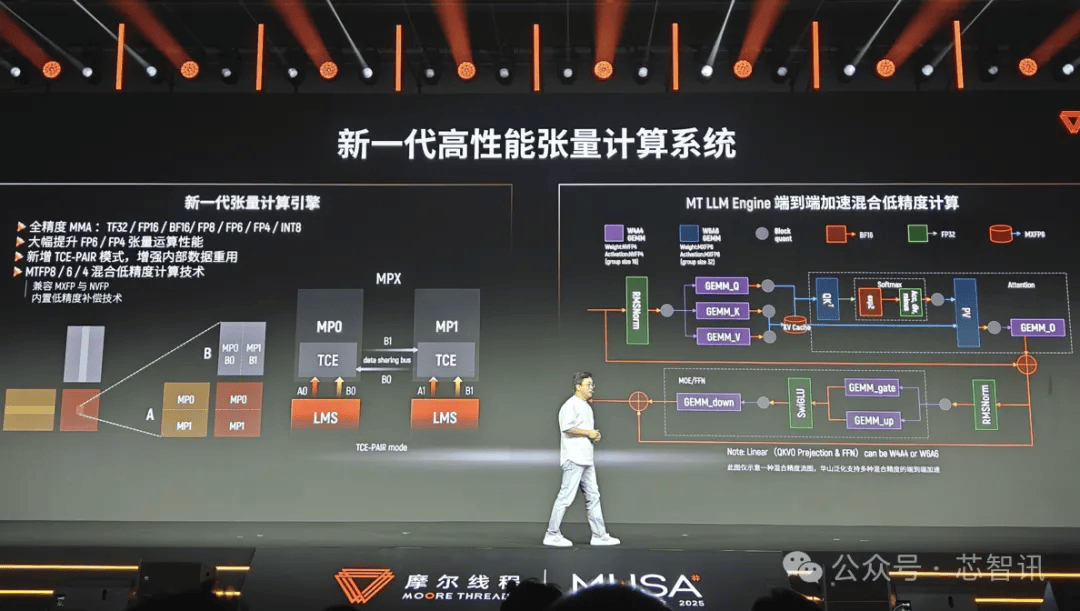
⦁ 非同期プログラミングと超大规模相互接続:新世代非同期プログラミングモデルを統合し、タスクスケジューリングと並列処理メカニズムを最適化。自社開発のMTLink高速相互接続技術により、10万カード規模を超えるインテリジェントコンピューティングクラスターの拡張をサポートする。

⦁ グラフィックスとAIの深い融合:AI生成型レンダリングアーキテクチャを内蔵し、ハードウェアレイトレーシング高速化エンジンを強化する。DirectX 12 Ultimateを完全サポートし、グラフィックスレンダリングとインテリジェントコンピューティングの高度な協調を実現する。

⦁ フルスタック自社開発とセキュリティ・信頼性:アーキテクチャはフルスタック自社開発に基づき、強固な特権的優位性を有する(2025年6月30日時点で、累計特許取得件数514件、うち発明特許468件)。フルスタック自社開発と自律制御の核心能力を備える。4層ハードウェアセキュリティアーキテクチャにより、チップからシステムまでの検証可能なセキュリティ保護を提供する。

「花港」アーキテクチャに基づく「華山(Huashan)」と「廬山(Lushan)」GPUの発表
Moore Threadsはさらに、将来的に「花港」アーキテクチャに基づき、高性能AI学習・推論統合チップ「華山」と高性能グラフィックスレンダリング専用チップ「廬山」を投入すると発表した。
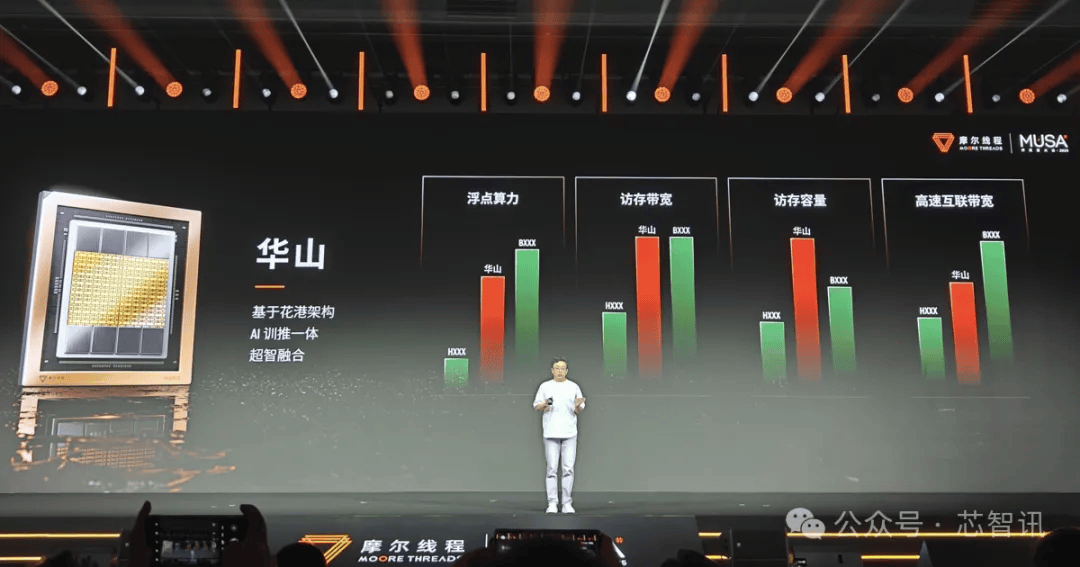
「華山(Huashan)」:AI学習・推論統合および超大规模インテリジェントコンピューティングに特化している。次世代非同期プログラミングと全精度テンソル計算ユニットを統合し、FP4からFP64までの全精度計算をサポート。万カード級インテリジェントコンピューティングクラスターに安定かつ高効率な演算サポートを提供し、次世代「AIファクトリー」構築の堅固な基盤となる。

「廬山(Lushan)」:高性能グラフィックスレンダリングに特化している。グラフィックス性能は全面的な飛躍を遂げ、前世代のS80グラフィックスカードと比較し、AAAゲーム性能は15倍、AI計算性能は64倍、ジオメトリ処理性能は16倍、テクスチャフィルレートは4倍、レイトレーシング性能は50倍、アトミックメモリアクセス性能は8倍、ビデオメモリ容量は4倍向上する。特に、AI生成型レンダリング、UniTE統一レンダリングアーキテクチャおよび次世代ハードウェアレイトレーシングエンジンを統合し、AAA級ゲームやハイエンドグラフィックス創作に強力な演算サポートを提供する。
(原文:https://www.icsmart.cn/100014/)