

エンボディドAI(Embodied AI)が人工知能(AI)の次の戦略的焦点となる中、基盤となる計算能力の自律的制御が特に重要となっている。このほど、Moore Threadsは北京BAAI人工知能研究院(Beijing Academy of Artificial Intelligence以下「BAAI」と略称)と共同で、FlagOS-Roboフレームワークに基づき、MTT S5000数千枚規模GPUスマート計算クラスターを活用し、BAAIが独自開発したエンボディドAIモデル「RoboBrain 2.5」のフルプロセストレーニングを成功裏に完了した。
これは業界初となる中国国産計算クラスターのエンボディドAI大規模モデル訓練における実用性と効率性の実証であり、中国国産AIインフラが複雑なマルチモーダルタスクへの対応において重要な一歩を踏み出したことを示す。多様なチップに対応する統一AIシステムソフトウェアスタック「FlagOS」とMTT S5000ハードウェアクラスターの効率的な連携により、このソリューションは「トレーニング可能」であるだけでなく、「安定かつ高速なトレーニング」を実現し、エンボディドAIが研究室から産業応用へと移行するための強固な基盤を提供した。
多次元評価による検証、指標の全面的な整合
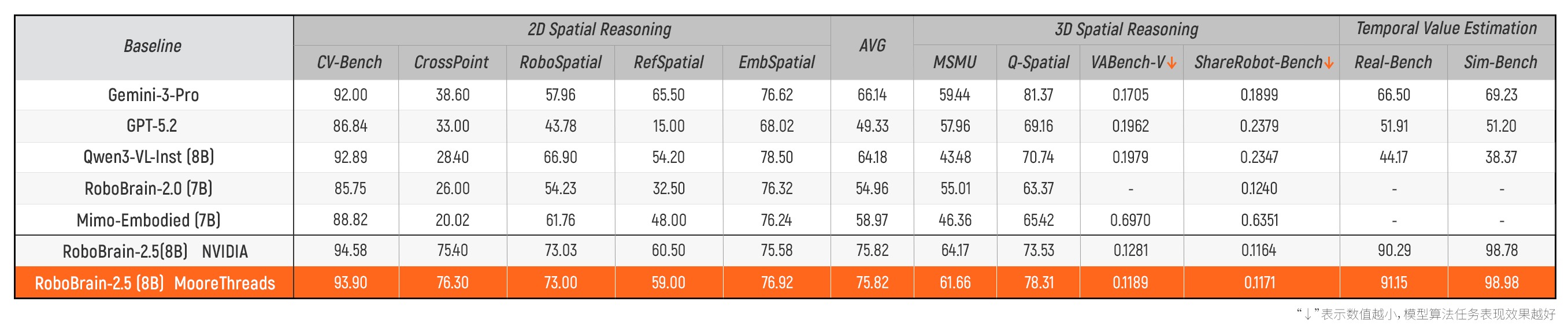
モデルアルゴリズムの効果を検証するため、BAAIチームは2D/3D空間知覚推論ランキング、時系列価値評価ランキングなど複数の権威あるエンボディド評価データセットで検証を実施。その結果、MTT S5000で訓練されたRoboBrain-2.5モデルは、複数の主要指標において国際主流GPU訓練モデルと同等の性能を示した。特にCrossPoint、Q-Spatial、VABench-Vタスクでは、アルゴリズム効果がより優れていることが確認された。この包括的な整合性を示す評価結果は、FlagOS-RoboフレームワークとMTT S5000の演算能力が協調して訓練した「エンボディド大脳」が、理解・計画・実行能力において業界トップレベルに達していることを示している。
損失関数の完全な整合、誤差0.62%未満
モデル精度において、MTT S5000ベースの夸娥インテリジェントコンピューティングクラスターは極めて高い安定性を示した。トレーニング曲線は、MTT S5000数千枚規模GPUクラスター上の損失関数の推移が国際的な主流GPUトレーニング結果と高度に一致し、相対誤差が0.62%未満であることを示している。この低誤差は中国国産計算リソースのトレーニング精度を示すと同時に、BAAIのFlagOS-Roboフレームワークがクロスプラットフォームでのロスレス移行を成功裏に実現したことを意味する。開発者はハードウェア変更によるモデル性能低下を懸念する必要がなく、「コード変更なし、精度低下なし」のシームレスな適応を真に実現している。
究極の線形スケーラビリティ、数千枚規模GPU加速比90%超
大規模クラスタートレーニングのコアは効率にある。今回のトレーニング実測データによると、Moore Threads MTT S5000数千枚規模GPU知能計算クラスターは高い拡張能力を示した:64枚から1024枚への拡張において、システムは90%以上の線形拡張効率を達成した。拡張曲線は極めて良好な線形成長傾向を示しており、これは計算リソースの増加に伴い、トレーニング速度がほぼ同期して倍増することを意味します。これは中国国産クラスターが大規模並列計算と通信スケジューリングにおいて成熟度を有し、万枚GPU規模のトレーニングをサポートする能力を備えていることを十分に証明している。
今回のMoore ThreadsとBAAIの深い協力関係は、エンボディドAIが研究室から産業応用へと移行するプロセスをさらに加速させ、業界に複製可能でスケーラブルな「中国国産計算力トレーニングパラダイム」を提供し、中国のエンボディドAI産業に自律的でオープンかつ効率的な計算基盤を提供する。
(原文:https://www.icsmart.cn/100826/)