

チップの世代が新しくなるごとにトランジスタ密度を高めることが難しくなる中、チップメーカーは、アーキテクチャの革新、チップサイズの大型化、マルチチップ設計、さらにはCerebrasのAIチップ「WSE」シリーズのようなウェハレベルチップなど、プロセッサの性能を向上させる別の方法を模索している。
このほど、中国科学院計算技術研究所の科学者たちは、RISC-Vアーキテクチャをベースにした先進的な256コアのマルチチップを開発し、これを1,600コアまで拡張して、ワイファイルサイズのチップを作成する計画を立てた。
The Next Platformの報道によると、中国科学院計算技術研究所の科学者たちは、最近の「Fundamental Research」誌で発表された論文で、「Zhejiang BigChip」と呼ばれる先進的な256コアのマルチチップ計算コンプレックスについて説明している。
このチップ設計は、16個の小さなチップから構成されており、各小チップには16個のRISC-Vコアがあり、オンチップネットワークを使用して従来の対称マルチプロセッサ(SMP)のように相互に接続される。これにより、小チップはメモリを共有することができる。各小チップには複数のチップ間インターフェースがあり、隣接する小チップに2.5D中間層を介して接続される。研究者は、この設計が100個の小チップまたは1,600個のコアにスケーラブルであることを示している。
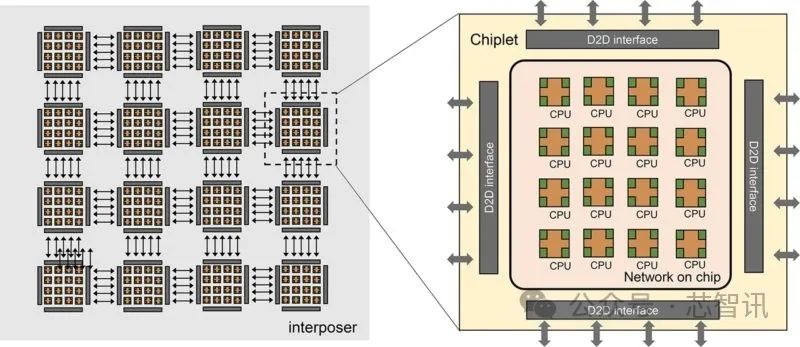
The Next Platformの報道によると、「Zhejiang BigChip」はChipletアーキテクチャに基づいており、22ナノメートルプロセス技術で製造される。現時点では、22ナノメートルの製造ノードで製造される1,600個のコアコンポーネントがどれだけの電力を消費するかはまだ確定していない。ただし、遅延の削減により、電力効率と性能が大幅に最適化されると予想されている。
論文では、リソグラフィとChiplet技術の制約について議論し、この新しいアーキテクチャが将来の計算要件を満たす可能性についても論じている。研究者は、マルチチップデザインがエクサスケールスーパーコンピュータのプロセッサ構築に使用できると指摘しており、AMDとインテルも現在この取り組みを行っていると述べている。
研究者は、「現在および将来のエクサスケール計算に対して、私たちは階層的なチップレットアーキテクチャが強力で柔軟な解決策になると予測している。階層的なチップレットアーキテクチャは、複数のコアと階層的な相互接続を持つ小さなチップで構成される。チップレット内では、コア間の通信に超低遅延の相互接続が使用され、小さなチップ間では先進的なパッケージング技術による低遅延の相互接続が使用される。これにより、スケーラビリティの高いシステムにおける小さなチップの遅延とNUMA効果を最小限に抑えることができる。」と述べた。
同時に、研究者たちは、このようなコンポーネントに複数レベルのメモリ階層を使用することを提案しているが、デバイスのプログラミングに困難をもたらす可能性がある。
「メモリ階層には、コアメモリ(キャッシュ)、オンチップメモリが含まれる。…これら3つのレベルのメモリは、メモリ帯域幅、レイテンシ、消費電力、コストの点で異なる。階層型チップレットアーキテクチャの概要では、複数のコアがクロススイッチを介して接続され、キャッシュを共有する。これはpod構造を形成し、podはチップレット内ネットワークで相互接続され、複数のpodはチップレットを形成し、チップレットはチップレット間ネットワークで相互接続され、さらにオフチップメモリに接続される。この階層構造を最大限に活用するには、慎重な設計が必要だ。異なるコンピュートレベルの作業負荷のバランスをとるためにメモリ帯域幅を合理的に利用することで、チップレットシステムの効率を大幅に向上させることができる。チップレットシステムの効率は、メモリ帯域幅を適切に利用し、異なる計算レベルの作業負荷のバランスをとることで大幅に改善できる。通信ネットワークリソースを適切に設計することで、チップレットが共有メモリ・タスクで協調できるようになる。」と研究者が述べた。
また、大規模なチップデザインでは、photo-electronicchip、Near-MemoryComputing、3Dスタックメモリなどの技術も活用できる。ただし、論文ではこれらの技術の具体的な実装の詳細や、このような複雑なシステムの設計と構築における課題解決については触れられていない。