

アリクラウド:大規模言語モデル学習のトレーニング用に自社開発したネットワーク設計を紹介
6月29日 - アリクラウドは最近、超大規模データ転送用の大規模言語モデル(LLM)のトレーニング専用に作成したイーサネット・ネットワークの設計を発表し、8ヶ月間実運用で使用している。
アリクラウドがイーサネットを選択したのは、一握りのベンダーへの過度の依存を避け、「イーサネット・コンソーシアム全体の力を活用し、より迅速な成長を実現したい」という思いからだ。この決定はまた、クラウドにおけるAI相互接続を独占するNVIDIAのNVlinkから逃れて、イーサネットをサポートし始めるベンダーが増えていることと一致しているようだ。
アリババのイーサネットネットワーキングに関する計画は、アリクラウドのシニアエンジニア兼ネットワーキング研究者であるEnnan ZhaiのGitHubページで明らかにされた。
アリクラウドのハイパフォーマンス・ネットワーキング(HPN)と呼ばれる国産の代替手段は、ECMPの存在を減らすことでハッシュの分極化を回避し、パス選択のための探索空間を大幅に縮小することで、大量のトラフィックに対応できるネットワークパスを正確に選択できるようにする。
HPNはまた、大規模な言語モデルを学習する際にGPUが連携して動作する必要があるため、AIインフラが単一障害点(特にトップ・オブ・ラック・スイッチ)の影響を受けやすいという事実にも対処している。
その結果、アリババのネットワーク設計では2台のスイッチを使用しているが、スイッチベンダーが推奨するスタック構成ではない。
この論文では、大規模な言語モデルのトレーニングにアリクラウドが使用する各ホストには、8つのGPUと9つのネットワーク・インターフェイス・カード(NIC)が搭載されており、それぞれに200GB/秒のポートが1組ずつ付いていると説明している。
NICの1つは、「バックエンドネットワーク」の日々のトラフィックを処理する。フロントエンド・ネットワークでは、ホスト・コンピュータ内の各GPUが、400~900GB/秒(双方向)で動作するホスト内ネットワークを介して他のGPUと直接通信できる。各NICは1つのGPU(アリユンは「トラック」と呼ぶ)に対応しており、この配置により各アクセラレータは「専用400Gb/秒RDMAネットワークスループット、総帯域幅3.2Tb/秒」で動作する。
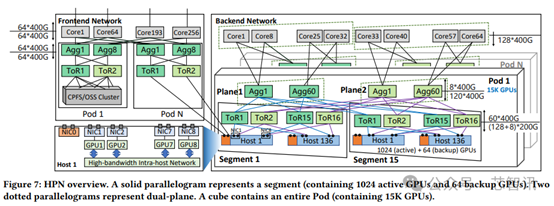
これはGPUのPCIe機能(PCIe Gen5×16)を最大限に利用するように設計されており、ネットワークの送受信容量を限界まで押し上げる」と論文では述べられている。
NICの各ポートは、単一障害点を避けるために、異なるトップ・オブ・ラック・スイッチに接続されている。アリクラウドがイーサネットを好むと述べたことは、AMD、ブロードコム、シスコ、グーグル、HPE、インテル、メタ、マイクロソフトにとって朗報であることは間違いない。これらのベンダーは最近、NVIDIAのNVlinkネットワーキング事業に挑戦することを目的としたUltra Accelerator Link(UALink)アライアンスに参加した。
IntelとAMDは、Ultra Ethernetのような他の先進的なネットワーキング・プロジェクトとともに、このアライアンスはAIワークロードをネットワーク化するためのより良い方法であると述べた。
しかし、アリクラウドのNPM設計はイーサネットをベースにしているとはいえ、NVIDIAの技術を利用している。 このNVIDIA NVlinkは、ホスト内ネットワーキング(ホスト間ネットワーキングよりも帯域幅が広い)に使用され、各ネットワーク・インターフェース・カードが異なるトップ・オブ・ラック・スイッチング・グループに接続される「レール最適化」設計アプローチも採用している。
アリクラウドはシングルチップ・スイッチを推し進め、同社が採用した51.2Tbit/秒のデバイスが従来のデバイスの2倍のスループットを持ちながら、消費電力は45%しか増加しないという事実を享受しているが、新しいデバイスは従来のデバイスよりも低温で動作するわけではない。
チップ温度が105℃を超えると、スイッチがシャットダウンする可能性がある。アリクラウドは、チップ温度を105℃以下に維持できる冷却システムを提供するスイッチ・ベンダーを見つけることができなかった。そこでアリユンは、独自のスチーム・チャンバー・ヒートシンクを開発した。
この論文では、「ウィック構造を最適化し、チップの中心により多くのウィックコラムを配置することで、熱をより効率的に伝導させることができる」と説明している。
この論文では、数千億のパラメータを持つLLMのトレーニングは、「大規模な分散トレーニングクラスタに依存しており、多くの場合、数千万のGPUを使用している」とも指摘している。
アリクラウド自身のQwenモデルには、1100億のパラメータで訓練されたバリエーションがある。つまり、同社はNPMを使用する多数のポッドと数百万のGPUを実稼働させており、モデルとデータセンターの規模が大きくなり、数が増えるにつれて、さらに必要になるという。