

2025-09-30
电子行业相关行业动态AI中国国产化
9月29日晚间,国产人工智能(AI)技术厂商深度求索(DeepSeek)宣布正式发布DeepSeek-V3.2-Exp模型,正如其名称所示的那样,这是一个基于V3.2实验性(Experimental)的版本。
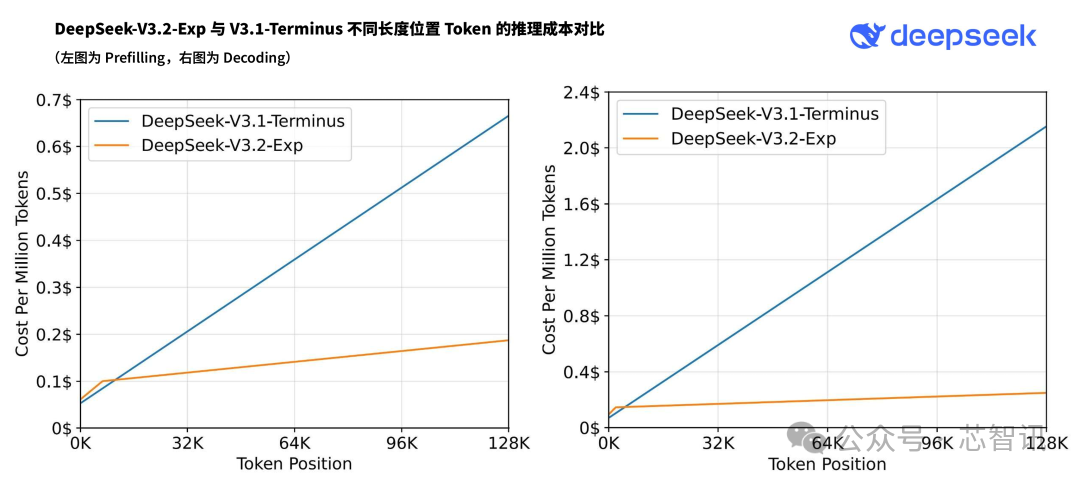
作为迈向新一代架构的中间步骤,Deepseek V3.2-Exp 在 V3.1-Terminus 的基础上引入了 DeepSeek Sparse Attention(一种稀疏注意力机制),针对长文本的训练和推理效率进行了探索性的优化和验证。
据介绍,DeepSeek Sparse Attention(DSA)稀疏注意力机制首次实现了细粒度稀疏注意力机制,在几乎不影响模型输出效果的前提下,实现了长文本训练和推理效率的大幅提升。
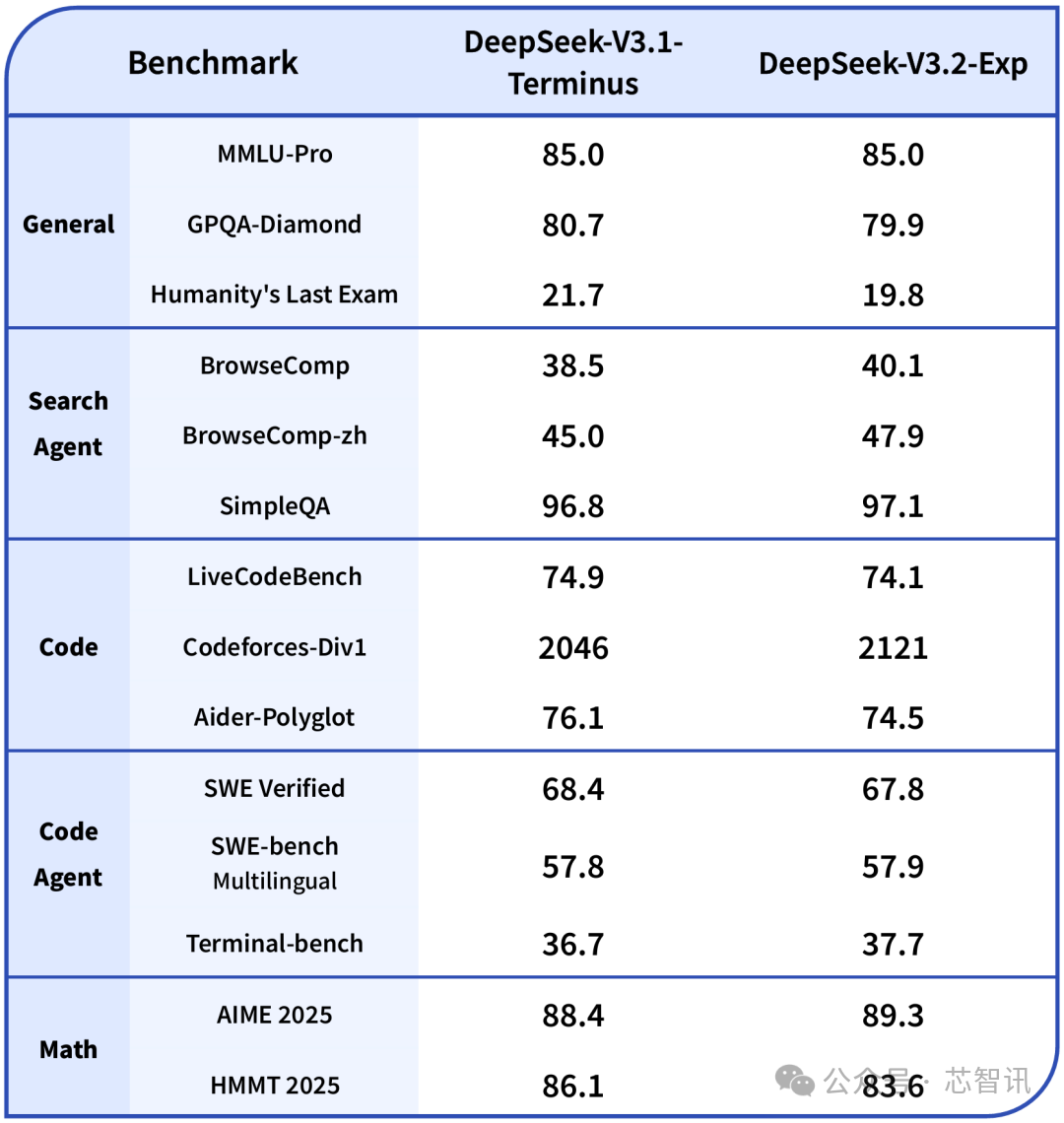
为了严谨地评估引入稀疏注意力带来的影响,我们特意把 DeepSeek-V3.2-Exp 的训练设置与 V3.1-Terminus 进行了严格的对齐。在各领域的公开评测集上,DeepSeek-V3.2-Exp 的表现与 V3.1-Terminus 基本持平。
目前,Deepseek官方 App、网页端、小程序均已同步更新为 DeepSeek-V3.2-Exp,同时 API 大幅度降价。
值得注意的是,在DeepSeek-V3.2-Exp模型发布的同一天,国产AI芯片大厂寒武纪就宣布,已同步实现对DeepSeek-V3.2-Exp的适配,并开源大模型推理引擎vLLM-MLU源代码。
目前,开发者可以在寒武纪软硬件平台上第一时间体验DeepSeek-V3.2-Exp的亮点。
寒武纪表示,公司一直重视芯片和算法的联合创新,致力于以软硬件协同的方式,优化大模型部署性能,降低部署成本。
此前,寒武纪对DeepSeek系列模型进行了深入的软硬件协同性能优化,达成了业界领先的算力利用率水平。
针对本次的DeepSeek-V3.2-Exp新模型架构,寒武纪通过Triton算子开发实现了快速适配,利用BangC融合算子开发实现了极致性能优化,并基于计算与通信的并行策略,再次达成了业界领先的计算效率水平。
寒武纪表示,依托DeepSeek-V3.2-Exp带来的全新DeepSeek Sparse Attention机制,叠加寒武纪的极致计算效率,可大幅降低长序列场景下的训推成本,共同为客户提供极具竞争力的软硬件解决方案。
(原文:https://www.icsmart.cn/96934/)