


12月17日,国产GPU厂商沐曦股份正式登陆科创板,上市首日高开568.83%,股价报700元/股。截止上午10:25分,盘中股价最高触及895元/股,涨幅超755%,市值突破3500亿元,超越当前的摩尔线程。
若按照开盘价700元/股计算,单签盈利近30万元。
此次沐曦股份发行价格为104.66元/股,是今年发行价第二高的新股(仅次于12月5日已上市的摩尔线程),共计发行4010万股的新股,预计募集资金总额为41.97亿元,扣除2.98亿元(不含增值税)的发行费用后,预计募集资金净额为38.99亿元。
一、全球GPU市场“一超一强”,国产GPU市场百花齐放
随着人工智能应用的快速普及,对于人工智能芯片的需求不断扩增,吸引越来越多的行业参与者,市场竞争日趋激烈。从全球范围来看,经过多年发展,已经基本形成了由英伟达和 AMD 组成的“一超一强”寡头垄断格局,两家企业在综合技术实力、销售规模、资金实力、人员数量等各方面优势明显;其中英伟达作为行业领导者,凭借其突出的产品性能、易用性以及完善的 CUDA 生态,构筑了坚实的竞争壁垒并持续扩大领先优势,占据超过 80%的全球市场份额。
沐曦股份也表示,GPU 设计是一项复杂的系统工程,涉及到硬件架构设计、IP/SoC 芯片设计、封装设计、软件架构设计、驱动程序及基础软件等多个不同专业领域,具有非常高的行业技术壁垒。目前包括沐曦股份在内的国产GPU总体上仍处于发展初期,在技术积累、产品性能、人员规模、产业化经验等各方面相比英伟达、AMD 等国际领先企业均存在较大差距。
近年来,受到美国对高性能 GPU/AI 芯片出口管制与国内自主可控市场发展等因素影响,海外厂商在中国市场的份额呈现明显下降趋势,本土品牌人工智能芯片的市场渗透率则呈显著上升趋势,但总体上仍处于发展相对初期阶段,尚未形成较明朗的竞争格局。
按不同技术路径划分,国内主要的GPU/AI芯片厂商包括以沐曦股份、海光信息、天数智芯、壁仞科技、摩尔线程等为代表的通用型计算架构(GPU)芯片设计企业,和以华为海思、寒武纪、昆仑芯、燧原科技等为代表的专用型计算架构(ASIC/DSA)芯片设计企业,呈现百花齐放态势。同时,随着人工智能芯片领域国产替代进程的不断加速,未来可能将有更多国内厂商进入到该市场参与竞争。
二、沐曦股份GPU累计销量超25000颗
根据招股书显示,沐曦股份成立于2020年,是国内高性能通用GPU产品的主要领军企业之一,致力于自主研发全栈高性能GPU芯片及计算平台,持续为国家人工智能公共算力平台、运营商智算平台、商业化智算中心等提供基础算力底座,推动人工智能赋能千行百业,并重点布局教科研、金融、交通、能源、医疗健康、大文娱等行业应用场景。目前,沐曦股份已成为国内高性能通用 GPU 的领导者之一,产品性能达到了国际上同类型主流高端处理器的水平,在国内处于领先地位。
沐曦股份认为,算力是推动数字经济发展的核心引擎,然而我国算力基础设施长期依赖海外巨头,面对不断升级的地缘政治摩擦和新一代人工智能革命,推进国产算力建设、保障产业链自主可控已迫在眉睫。
自成立以来,沐曦股份持续深耕 GPU 和人工智能行业,沐曦创始团队凭借深厚的 GPU 技术及全流程量产经验,形成了一支深刻洞察全球 GPU 行业技术发展趋势,具有持续自主创新能力的技术研发团队。在团队不懈的技术攻坚下,沐曦股份成为了国内少数几家全面系统掌握了通用 GPU 架构、GPU IP、先进制程 GPU 芯片及其基础系统软件研发、设计和量产核心技术的企业之一。
沐曦股份 GPU 产品基于自主研发的 GPU IP 与统一的 GPU 计算和渲染架构,在通用性、单卡性能、集群性能及稳定性、生态兼容与迁移效率等方面具备较强的核心竞争力,产品综合性能已处于国内领先水平。
目前,沐曦股份的主要产品全面覆盖人工智能计算、通用计算和图形渲染三大领域,报告期内先后推出了用于智算推理的曦思 N 系列 GPU、用于训推一体和通用计算的曦云 C 系列 GPU,以及正在研发用于图形渲染的曦彩 G 系列 GPU。

单卡性能方面,沐曦股份是国内首批具备先进制程 GPU 芯片设计能力和商业化落地能力的企业之一,全栈 GPU 产品基于自主研发和自主知识产权的 GPU IP、GPU 指令集和架构,单卡性能处于国内第一梯队;集群性能方面,公司自研的 MetaXLink 具备国内稀缺的高带宽卡间互连能力,可实现 2-64 卡多种互连拓扑,并且在智算集群的线性度和稳定性方面具有较强的产品表现。
沐曦股份称,其旗舰产品曦云 C 系列训推一体 GPU 芯片基于全自研的 GPU IP、指令集和架构,在通用性、单卡性能、集群性能及稳定性、生态兼容与迁移效率等方面均达到国内领先水平,具备较强的综合竞争力。
软件生态方面,沐曦股份自主构建的 MXMACA 软件栈不仅拥有统一、完整且高效的全栈式工具链,涵盖应用开发、功能调试和性能调优等核心环节,同时高度兼容 GPU 行业国际主流 CUDA 生态,能够开放拥抱全球开发者丰富的开源成果,具有较高的易用性和迁移效率,在通用性和灵活性上具备独特的竞争力。软硬件的深度协同确保了公司产品性能的高效释放,为沐曦股份塑造了深厚的竞争壁垒。
在商业应用方面,沐曦股份是国内少数真正实现千卡集群大规模商业化应用的GPU 供应商,并正在研发和推动万卡集群的落地,目前已成功支持 128B MoE大模型等完成全量预训练。沐曦股份与整机服务器、操作系统、运维管理平台、主流AI 框架、主流大模型等上下游生态广泛适配。凭借突出的产品性能和稳定的供应能力,截至报告期末,沐曦股份 GPU 产品累计销量超过 25,000 颗,并已在多个国家人工智能公共算力平台和商业化智算中心实现规模化应用。
据介绍,沐曦股份目前正是深度构建“1+6+X”生态与商业布局,基础算力底座方面相继交付 9 大智算集群,算力网络覆盖国家人工智能公共算力平台、运营商智算平台和商业化智算中心,区域横跨北京、上海、杭州、长沙、中国香港等地区,并逐渐向更多区域延伸。
三、拟募资39亿元,发力高性通用GPU
此次沐曦股份IPO拟募资约39亿元,其中,24.59亿元用于“新型高性能通用GPU研发及产业化项目”、4.53亿元用于“新一代人工智能推理GPU研发及产业化项目”和9.91亿元用于“面向前沿领域及新兴应用场景的高性能GPU技术研发项目”。
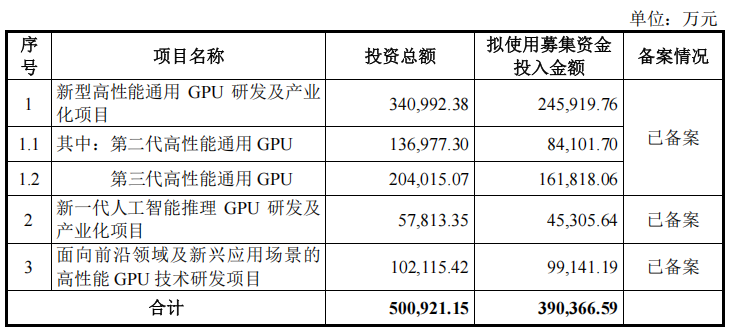
沐曦股份表示,本次募集资金投资项目均紧紧围绕公司主营业务,募集资金投资项目符合国家相关的产业政策,有利于扩大公司整体规模并扩大市场份额,进一步提高公司竞争力和可持续发展能力,有利于实现并维护股东的长远利益。